在爬虫爬网页的时候,需要避免重复抓同一个网页,来提高爬取效率,避免不必要的开销,这就需要使用一些判重的方法。
数据库
一种比较常见的方法是用数据库。这也是实现分布式爬虫去重的一个比较简单的方案。简单来说就是多个爬虫可以共享同一个数据库,把爬过的url写进去,在爬url前从数据库里查询是否已经写入。
持久化问题数据库已经帮忙处理掉了。同样可以使用类似上面的摘要算法对url的数据量进行优化。
优点很明显,可以比较简单的实现多个爬虫的合作任务。缺点同样很明显,随着数据量的增加,去重的效率将越来越低,严重影响爬取的效率。
Hash Table
另一种比较简单的方式是使用哈希表这种数据结构,比如python中使用set,go中使用map。在每次爬取启动时新建一个哈希表,在爬取过程中将爬过的丢进去,后面每次爬一个url的时候先在哈希表里检查一下是否已经存在这个值,如果已经爬过了就直接把任务丢弃掉。
这个方案也可以稍微优化,url一般会比较长,因此可以在存储和检查哈希表的url之前,先通过一个摘要算法处理,比如md5,sha1之类的,来减少需要存储的数据量。
如果需要持久化的话,就需要把这个哈希表dump成文件,下次使用时再load回来。
这种方法实现起来比较简单,使用比较方便,效率也非常高。适合规模比较小的爬取任务。缺点是一旦爬取的任务量太大,内存会吃不消。
可以借助Redis来实现分布式。
Bloom Filter
就是布隆过滤器。刚听说的时候,以为是这东西叫bloom是因为发明者是个文艺青年,后来发现是这个人叫Bloom =。=
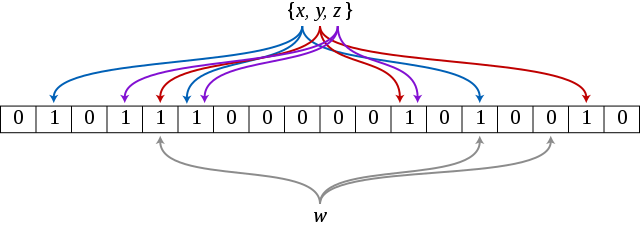
Bloom filter实际上是由一个bitmap和若干个哈希函数构成的。它可以用来高速检查一个元素是否可能在集合中,并且空间占用要比上面的方法少很多,但只能向Bloom filter里添加元素,却没法删除,并且随着里面的数据量增大,会有一定程度的误报。因此这是一个用错误率换时间和空间的方法。
它的原理是将一个元素通过k个哈希函数,将元素映射为k个比特位,在bitmap中把它们置为1。在验证的时候只需要验证这些比特位是否都是1即可,如果其中有一个为0,那么元素一定不在集合里,如果全为1,则很可能在集合里。(因为可能会有其它的元素也映射到相应的比特位上)同时这也导致不能从Bloom filter中删除某个元素,无法确定这个元素一定在集合中。以及带来了误报的问题,当里面的数据越来越多,这个可能在集合中的靠谱程度就越来越低。(由于哈希碰撞,可能导致把不属于集合内的元素认为属于该集合)
可以使用这个计算器来计算容量和错误率。
Bloom filter就很适合用来做URL的去重工作,它由于空间占用及查询效率方面的优势,也经常用在垃圾邮件过滤以及数据库查询等场景中。
大部分常用的语言中都有人已经实现了Bloom filter库,可以直接拿来使用。另外在分布式场景下,也可以将Bloom filter与Redis结合使用。
但是还要重新强调一下,Bloom filter是有一定的误报的几率的,只有在不需要太精确判断的场景下才可以使用。
其他杂项
Scrapy框架里存在一个默认开启的去重过滤器:RFPDupeFilter。他通过scrapy.utils.request.request_fingerprint函数生成请求的指纹,对于请求的method,url,body等进行sha1哈希,并进行判重。可以适合关掉或者用其他过滤器进行过滤,也可以通过继承BaseDupeFilter实现自己的过滤器。
传送门