今天我们来学习一个用来装逼的新概念。
Change Data Capture(缩写为CDC)——大概可以机翻为“变动数据捕获”——你可以将它视为和数据库有关的架构设计模式的一种。它的核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入,更新,删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
适用场景
我们可以把CDC认为是数据库事件驱动的一种数据/信息分发系统,CDC主要适用于以下的场景:
异构数据库之间的数据同步或备份/建立数据分析计算平台
在MySQL,PostgreSQL,MongoDB等等数据库之间互相同步数据,或者把这些数据库的数据同步到Elasticsearch里以供全文搜索,当然也可以基于CDC对数据库进行备份。而数据分析系统可以通过订阅感兴趣的数据表的变更,来获取所需要的分析数据进行处理,不需要把分析流程嵌入到已有系统中,以实现解耦。
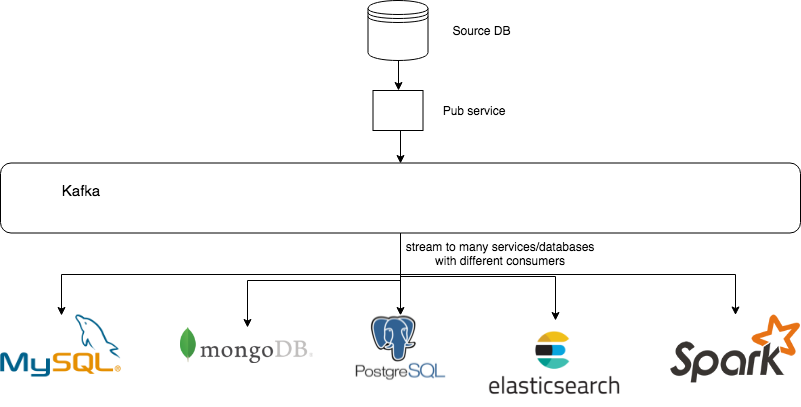
微服务之间共享数据状态
在微服务大行其道的今日,微服务之间信息共享一直比较复杂,CDC也是一种可能的解决方案,微服务可以通过CDC来获取其他微服务数据库的变更,从而获取数据的状态更新,执行自己相应的逻辑。
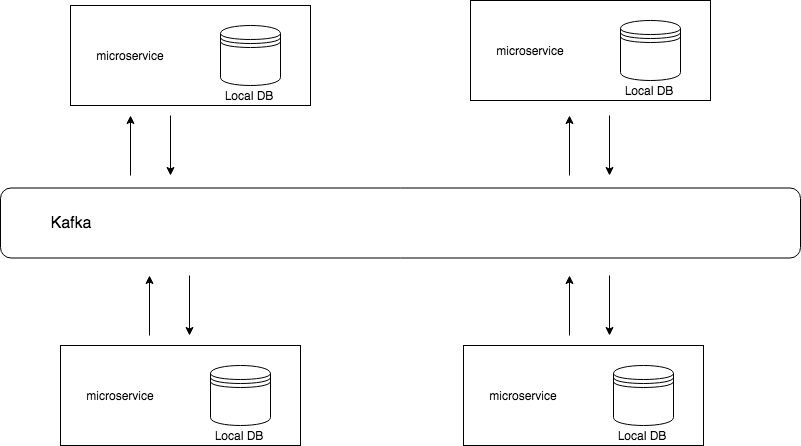
更新缓存/CQRS的Query视图更新
通常缓存更新都比较难搞,可以通过CDC来获取数据库的数据更新事件,从而控制对缓存的刷新或失效。
而CQRS是什么又是一个很大的话题,简单来讲,你可以把CQRS理解为一种高配版的读写分离的设计模式。举个例子,我们前面讲了可以利用CDC将MySQL的数据同步到Elasticsearch中以供搜索,在这样的架构里,所有的查询都用ES来查,但在想修改数据时,并不直接修改ES里的数据,而是修改上游的MySQL数据,使之产生数据更新事件,事件被消费者消费来更新ES中的数据,这就基本上是一种CQRS模式。而在其他CQRS的系统中,也可以利用类似的方式来更新查询视图。
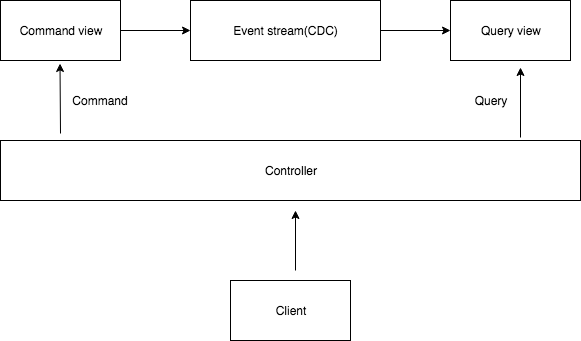
整体架构
数据源
数据库(即数据源)需要能完整地记录或输出数据库的事件(数据或数据表的变动)。例如MySQL的binlog,MySQL通过binlog(二进制日志)记录数据库的变动事件,而MySQL本身可以借助binlog来实现主从复制。其实CDC本身也只是把这种机制扩展了一下,使之能够作为更广泛的用途。
大部分数据库都有类似的机制:
- MySQL: binlog
- PostgreSQL: Streaming Replication Protocol
- MongoDB: oplog
等等。
发布服务(生产者)
这东西现在没有一个明确的名称,这里就暂且称为发布服务。它的功能是解析数据源输出的流式数据,序列化成统一的封装格式,并输出到数据总线中。
Maxwell
zendesk/maxwell,专为MySQL数据源使用,它能够读取binlog,将数据库变更序列化为JSON,输出到Kafka, Kinesis, RabbitMQ, Google Cloud Pub/Sub, Redis等消息队列中。它还提供了bootstrap命令,支持将某张表全量数据输出作为起始数据。
Debezium
debezium/debezium,目前支持监听MySQL,MongoDB,PostgreSQL,Oracle,SQL Server等数据库的变化,但消息中间件只能使用Kafka。它的数据交换默认采用Avro格式,这种格式对数据schema的变更比较友好。目前还处在开发阶段,所以文档不是特别完善,但似乎已经有勇敢的公司用在生产环境中了。
canal
alibaba/canal,它能解析binlog并输出,可以利用它提供的client来实现自己的订阅消费逻辑,但这个项目不涉及到输出到通用的消息中间件,因此适用范围较窄。最近看了一下发现有了更新,支持输出到kafka,甚至还带一些监控功能,看起来很强。
自行实现
你需要的是一个能够解析数据库输出流的库,比如noplay/python-mysql-replication这种,基于这样的库来实现发布服务。
我曾经写过py-mysql-elasticsearch-sync这样一个工具,就是为了解决把MySQL的数据同步到Elasticsearch这样的任务,可以把这东西视为弱鸡版的CDC(因为中间没有通过数据总线发布,而是直接写入ES了)。其中就使用了python-mysql-replication这个库来获取数据库变更,它的原理就是将自己伪装成一个MySQL Slave数据库,通过解析binlog获取数据变更的事件。(和canal原理上差不多)
数据总线(消息中间件)
数据总线这部分是一个消息中间件,一般会选Kafka,RabbitMQ,Redis之类的,但大部分做CDC都会选用Kafka。

Kafka官方并不把自己称为消息队列,而是叫“distributed streaming platform”,的确,目前kafka的能力以及演化方向更像是一个数据处理的平台了,而不仅仅是消息中间件,你可以利用Kafka Streams来进行一些数据处理。
在整个CDC里,Kafka会作为核心的数据交换组件,或者你可以把它称为数据总线,kafka集群的健壮性和吞吐量能够支撑海量数据的pub/sub,并且能够将写入的数据持久化一段时间,发布服务将数据库任何数据变动写入Kafka,由不同的消费者在上面同时进行订阅和消费,如果有需要,消费者随时可以把自己的offset往前调,对以往的消息重新消费。
消费者
消费者部分根据场景而不同,通常只要使用相应消息队列的客户端库实现消费者,根据生产者生成的消息格式进行解析处理即可,例如你用Kafka作为队列,那么在Python中可以用confluentinc/confluent-kafka-python之类的库来进行实现。
而需求比较简单的话可以使用直接现成的开源工具,比如Kafka的一些Sink Connectors。
如果有特殊的需求,可以自行实现类似的生产者,消费者(或者借助已有的工具进行改造),将数据变动通过Kafka之类的消息总线进行发布,来自定义自己的CDC系统。
参考
工程師幹話里讲:
我們首先要取一個好名字,我們需要一個看起來每個字都看得懂,但是加在一起別人就搞不懂你到底要做什麼名字。名字很重要,成長停滯的公司就像有了點錢但是性能力下降的中年男子,看到名字很厲害的壯陽藥就會亂投藥。