《Practical BM25》系列文章来自于elastic官方博客,共分为三部分,讲解了Elasticsearch的默认相似度算法BM25的原理。本篇为第二部分的中文翻译,原文链接 Practical BM25 - Part 2: The BM25 Algorithm and its Variables
目录
BM25 算法
本文中我会深入数学细节,以足以解释究竟发生了什么,但这只是通过分析BM25公式的结构,探究究竟发生了什么的部分。首先我们看一下公式的整体,随后我们对于每个组成部分进行分别讲解:
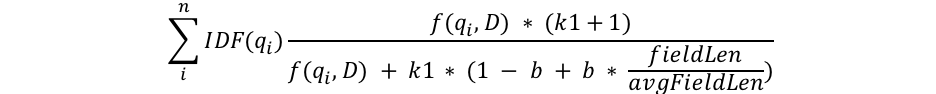
我们可以看到,公式中有一些东西经常出现,如qi, IDF(qi), f(qi,D), k1, b, 以及关于field长度的变量。下面是这些变量代表的意义
-
qi 代表第i个查询term
例如,在搜索"shane"时,只有1个查询term,所以q0就是"shane"。如果我搜索的是"shane connelly",Elasticsearch会根据空格,将这个字符串分词为2个term,q0是"shane",q1是"connelly"。这些查询term被用在其他的一些方程中,它们最终会被求和。 -
IDF(gi) 代表第i个查询term的逆文档频率(Inverse Document Frequency)
对于之前接触过TF/IDF的同学,IDF这个概念你应该很熟悉。如果不熟悉的话,也不要担心。(只要记住TF/IDF中的IDF和BM25中的IDF是有区别的就行了) 我们的公式中的IDF衡量了在所有文档中一个term的出现频率,并“惩罚”了常见的term。 Lucene/BM25在这一部分实际用的公式是
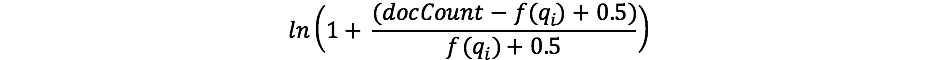
这里的docCount是分片中存在这个字段有值的文档总数(如果你用了search_type=dfs_query_then_fetch这个参数,那么就是各分片中的总数),而f(qi)是包含第i个查询term的文档数量。在我们的例子中,"shane"在所有四篇文档中都有出现,所以对于"shane"这个term,最终的IDF("shane")是
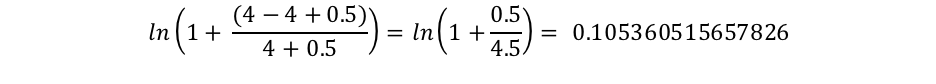
而"connelly"只在两篇文档中出现,因此IDF("connelly")的值是
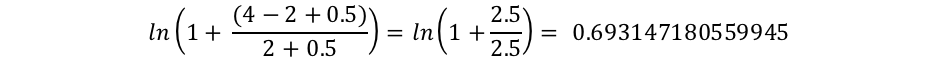
我们能发现,对于包含更稀有的term("connelly"比在所有文档中都出现的"shane"要更稀有)的查询,乘数将更大,因而对最终评分的贡献更大。这给人的直观感受是:"the"这个term可能出现在几乎所有英文文档中,因此当一个用户在搜索"the elephant"时,"elephant"可能才是更重要的——我们希望这个词对评分有更大的贡献——比"the"这个term更多(因为它几乎出现在所有文档中)。 -
我们看到在分母中有一项,是字段的长度除以了平均字段长度,fieldLen/avgFieldLen。
我们可以把它认为是将文档长度与平均文档长度做比较。如果一篇文档比平均长度长,那么整个公式的分母就会变大(减小最终评分),如果文档比平均长度短,公式的分母会变小(增大最终评分)。注意Elasticsearch对字段长度的实现是基于term的数量(而不是字符长度之类的东西),这和原本的BM25论文中描述的一致,但我们有个特殊的flag(discount_overlaps),可以在你需要的时候,对同义词进行特殊对待。 我们可以这样理解,文档中term越多——至少是未匹配查询的那些term——那么得分就会越低。 这又给人了一种直观感受:如果一篇文档有300页,但其中仅提到我的名字一次,看起来就不如一条很短的推特提到了我的名字来得重要。 -
我们能看到分母中有个变量b,它与我们刚才讨论的字段长度之比相乘。 如果b更大,那么文档的长度与平均长度的比值对结果的影响就会被放大。 为了证明这一点,你可以想象如果b的值是0,那么这个长度比值会完全被抵消,它对评分就完全没有影响了。在Elasticsearch中,b的值默认为0.75
-
最后,我们能看到有两个部分k1和f(qi,D),它们在分子和分母中都有出现。由于在两边 都有出现,我们就很难仅通过看这个公式了解它们的作用,我们开始研究吧。
- f(qi,D)表示“第i个查询term在文档D中出现多少次?”在所有的这些文档中,f(“shane”,D)是1,f(“connelly”,D)的值各不相同:对于文档3和4,它的值是1,对于文档1和2这个值是0。如果有以“shane shane”为文本的文档5,那么f(“shane”,D)的值是2.我们在分子和分母中都能看到f(qi,D)的身影,还有个特殊的"k1"因子,我们后面会讲到它。 我们可以认为f(qi,D)代表了查询term们在一篇文档中出现的次数越多,则最终的得分越高。 这给我们一种直观的感受:那些有很多我们名字的文档比仅出现一次的那些文档与我们的相关性更强。
- k1是用来帮助确定词频饱和特征点的。它限制了单一的查询term能够对给定文档的得分有多大程度的影响。它通过渐近线来达到这个目的。BM 25与TF/IDF的比较如下
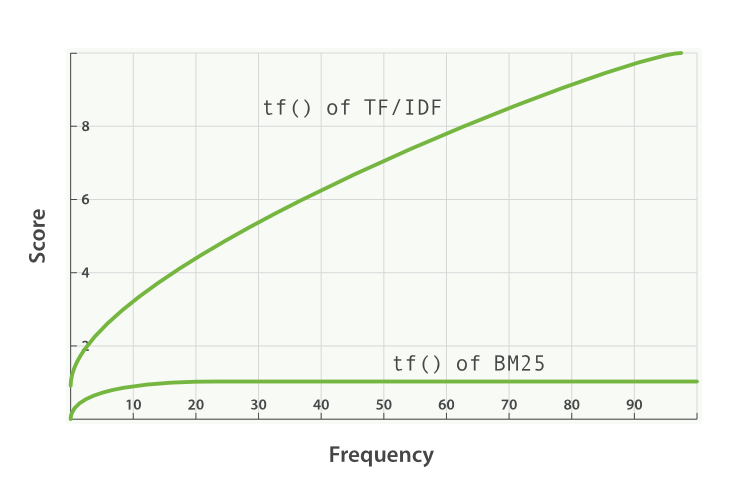
一个更高/更低的值意味着BM25的tf()曲线的斜率变化。这具有改变“term出现更多次数增加了更多的分数”的效果。对k1的一种解释是,它是对于一篇平均长度的文档,选定term的分值到达最大分值一半时词频(TF)的值。当tf() ≤ k1时,tf对于得分的影响的曲线增长得比较快,而tf() > k1时,曲线就比较平缓。
继续我们的例子,k1帮助我们解决了“将第二个"shane"加入到文档时会比它第一次出现这个词多加多少分数,或者第三次会比第二次多加多少”这个问题。更高的k1意味着每个term会因为相对更多的出现次数可以让得分更高。当k1为0时,意味着除了IDF(qi)之外,公式的其他成分都会被无效化掉。Elasticsearch在默认情况下,k1的值是1.2。
带着新知识回顾我们的搜索过程
我们要删掉people索引,并将它重建为只有1个分片的索引,这样我们就不需要设置search_type=dfs_query_then_fetch参数了。接下来,我们要建立三个索引来验证我们所学:第一个索引是k1=0、b=0.5,第二个索引(people2)是b=0、k1=10,第三个索引(people3)是b=1、k1=5。
DELETE people
PUT people
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0.5,
"k1": 0
}
}
}
}
}
PUT people2
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0,
"k1": 10
}
}
}
}
}
PUT people3
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 1,
"k1": 5
}
}
}
}
}
现在我们向三个索引中插入一些文档:
POST people/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people2/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people3/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
那么,当我们进行这样的查询时:
GET /people/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
我们看到在people这个索引中,所有文档的分数都是0.074107975。这个匹配中,k1的值为0:只有搜索term的IDF对评分有影响!
现在来试试people2,它的b=0,k1=10
GET /people2/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
在结果中我们能发现两件事情。
第一,我们发现评分是按照"shane"出现的次数排列的。文档1,2,3,4中"shane"都仅出现一次,它们的得分都是0.074107975。文档5中"shane"出现两次,由于f(“shane”,D5) = 2,因此它的分数更高(0.13586462)。文档6中由于f(“shane”,D6) = 3,它的分数还要更高(0.18812023)。这符合我们对b设置为0时的直觉:文档的长度——或者文档中term的数量——不会影响分数;评分只与匹配的term的数量相关。
第二件事情是,这些得分之间的差是非线性的,尽管这6篇文档的得分看起来非常接近线性。
- 未出现查询term和第一次出现的分数差是 0.074107975
- 出现两次查询term的得分与出现一次之间的分数差是 0.13586462 - 0.074107975 = 0.061756645
- 出现三次查询term的得分与出现两次之间的分数差是 0.18812023 - 0.13586462 = 0.05225561
0.074107975非常接近0.061756645,而后者又非常接近0.05225561,但很明显它们减小了。因为k1非常大,才让它们看起来几乎数线性的。我们至少可以从出现次数增加中看出它不是线性的——如果是线性的,差值应该完全相同。我们在验证过people3索引后会来回顾这一点。
下面我们验证people3,它的参数是k1 = 5并且b = 1。
GET /people3/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
我们得到了如下结果:
"hits": [
{
"_index": "people3",
"_type": "_doc",
"_id": "1",
"_score": 0.16674294,
"_source": {
"title": "Shane"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "6",
"_score": 0.10261105,
"_source": {
"title": "Shane Shane Shane Connelly Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "2",
"_score": 0.102611035,
"_source": {
"title": "Shane C"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "4",
"_score": 0.102611035,
"_source": {
"title": "Shane Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "5",
"_score": 0.102611035,
"_source": {
"title": "Shane Shane Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "3",
"_score": 0.074107975,
"_source": {
"title": "Shane P Connelly"
}
}
]
可以看到,在people3中,匹配term("shane")与非匹配term的比率是影响相关性评分的唯一要素。因此像文档3这种3个term中只匹配1个term的文档,要比2, 4, 5, 6这些几乎一半数量term都被匹配了的文档的得分要低,而前述所有文档,得分都不如文档1高,因为文档1整个文档被完全匹配了。
要记住,在people2和people3中,高分和低分文档之间分数差别很大。这(再次)归功于很大的k1值。我们可以尝试删掉people2/people3然后以k1=0.01之类的值重建这些索引,来进行一个额外的练习,你会发现文档之间的得分差距更小了。在 b = 0 并且 k1 = 0.01 时:
- 未出现查询term和第一次出现之间的分数差是0.074107975
- 出现两次查询term的得分与出现一次之间的分数差是 0.074476674 - 0.074107975 = 0.000368699
- 出现三次查询term的得分与出现两次之间的分数差是 0.07460038 - 0.074476674 = 0.000123706
当k1=0.01时,我们能看到每次出现的增加,对得分的影响的衰减要比 k1 = 5 或 k1 = 10 的时候快得多。第四次出现时,将比第三次加的分数更少。换句话说,较小的k1值会使term的评分更快饱和。而这正是我们想要的结果。
希望这篇文章能帮助你理解这些参数是如何处理众多文档集合的。有了这些知识以后,我们下一步会学习怎样选择合适的b和k1的值,以及Elasticsearch如何提供工具来理解评分并迭代你的方法。